在深入 Cilium 的世界前,你將發現有非常多的概念會和 eBPF 掛鉤,如果在一個「不理解 eBPF 怎麼運作的情況下」去學習 Cilium,我認為學習過程中會似懂非懂的學過去。
還記得我們在 Day 1 的文章用一小段很簡單的話說明 eBPF 是什麼
在不用重新編譯 Linux Kernel 或是修改 Linux Kernel 程式碼的情況下,安全地掛載一段自訂程式碼到 Kernel 中的特定點 (hook points)
為什麼不用修改 Kernel 程式碼?為什麼會說「安全地」?hook point 又是什麼?
BPF (Berkeley Packet Filter) 其實有分 cBPF (classic) 和 eBPF (extended),簡單來說就是傳統的和新版的,本系列文除非特別說明是 “c”BPF,否則只要看到 BPF 都是指 eBPF
老實說我一開始學 eBPF 的時候看到名字就覺得就覺得很霧煞煞,字面上感覺是一個封包過濾的工具,但是看起來能做的事情已經超出封包過濾的範疇,所以這名字就給人一種「圖文不符」的感覺,學習完之後,我可以很肯定的說「真的是圖文不符」但是有一些歷史因素的。
tcpdump 是在 1988 年而誕生,當時會需要把封包從 kernel Copy 到 user space 做 filter 所以效能很差,因此有了在 Kernel 那邊就實作 filter 的想法,所以在 1992 年 cBPF 誕生,當時就是為了提升 tcpdump 效能而生,實作方式是「把過濾條件 compile 成 BPF bytecode,丟進 kernel 執行」,所以是可以在封包進來後,很早期的階段就把封包過濾掉,這樣就可以知道為什麼會被命名成 Packet Filter 了吧,關於 1992 年 cBPF 與 tcpdump 效能優化的細節可以參考這篇論文。
從上面的小故事,我覺得已經點出幾個很重要的概念了:
到了 2014 左右,Linux 社群(特別是 Alexei Starovoitov 等人)開始推廣 extended BPF(eBPF),把它擴展成一個通用的 kernel extensibility framework,重要概念還是跟前面一樣的,只是已經不侷限於 Packet Filter 了,而是在 Networking, Security, Profiling, Observability… 等領域都可以使用到 eBPF,而且還加入了 JIT 編譯、map 資料結構、verifier 驗證機制,所以讓 eBPF 變成一個安全的 runtime,這也是為什麼會「圖文不符」
推薦影片:eBPF 紀錄片
在前面講 BPF 的誕生,其實就有提到會把某東西編譯成 BPF Bytecode,所以其實關鍵在於有沒有對應的 Compliler 能幫你把 Code 編譯成 BPF Bytecode,目前的主流就是 「寫 C 語言然後用 LLVM/Clang 編譯成 BPF Bytecode」,至於 Cilium 你說是用 Golang 寫的?其實是 Golang 寫一些 Control Plane 的元件,但是要載入到 Kernel 的 eBPF Program 仍是用 C 寫,然後再編譯成 BPF bytecode,可以到 Cilium 的 GitHub 找到 /bpf 目錄,這裡就是 C 寫出來的然後會被編譯成 BPF Bytecode。
另外簡單提一下 Bytecode 的內容:BPF 定義了一套屬於自己的 RISC 型指令集,Bytecode 其實就是依照這套指令集編譯出來的指令,詳細內容推薦可以閱讀這份文件。
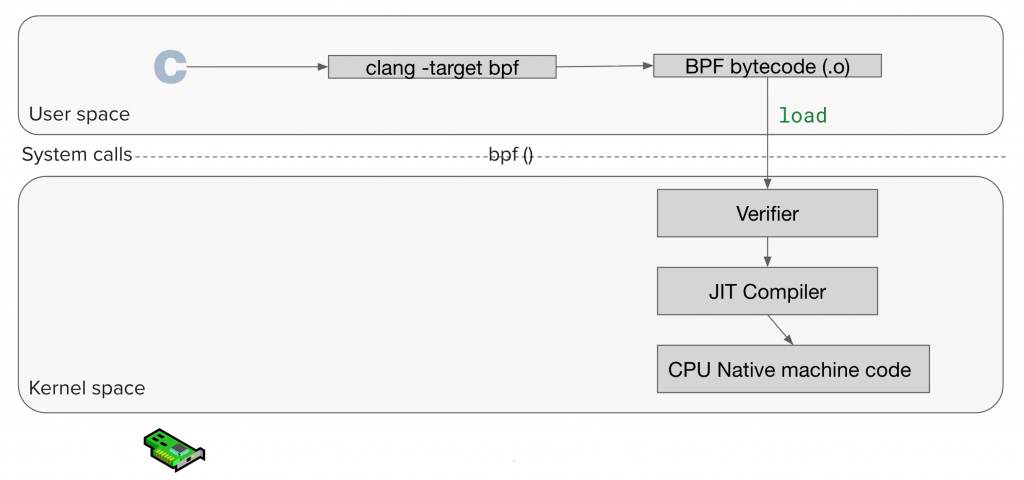
我們前面聊的那些,大概就會有一個感覺如下面這張圖,C -> Clang 編譯 -> BPF Bytecode:

其實到這裡已經掌握 BPF Program 的開發流程了,我們接下來要解決的是「怎麼丟到 Kernel 執行?」
要丟到 Kernel 執行,就必須先提到一個名詞叫做 “Load”,中文我通常會說「載入」,所謂的 Load 就是把 BPF Bytecode 載入到 Kernel,要做到這件事情,會使用 bpftool 這個工具,其實這背後都是呼叫 bpf() system call 來達到 “Load” 這個動作,甚至我可以直接跟你說,所有 BPF 的操作都離不開 bpf() system call,再怎樣的工具,底層一定依賴 bpf() system call, bpf() 可以傳入哪些 Command 可以參考這份文件。
當 “Load” 執行下去之後,會先碰到一個叫做 Verifier 的東西,它會做一些安全性的檢查,畢竟你寫出來的程式碼是要被放到 Kernel 執行的,你不可以隨意亂存取不該存取到的記憶體,你不能寫出停不下來的程式碼 (無窮迴圈)。
檢查通過之後,會依照你的 Linux Kernel Kconfig 的 CONFIG_BPF_JIT_ALWAYS_ON 選項是否有開啟,通常大多數預設都是有開啟的,如果有開啟,Verifier 的下一站遇到的就是 JIT Compiler,JIT Compiler 會幫你把 BPF Bytecode 編譯成 native machine code (例如你 CPU 是 arm64 架構,那就編譯成 AArch64 指令),因為被編譯成 Machine Code ,CPU 可以直接執行,所以效能會有所提升,如果沒有 JIT,kernel 只能用 interpreter 模式,一條一條解釋 bytecode,效能會比較慢。
到這邊已經成功 Load eBPF Program 到 Kernel 了,但是載入後要怎麼執行?這時候就要講講 “attach“ 和 “hook point”
為了方便理解,你可以把 hook point 想像成 Linux kernel 裡預先留好的「洞」:
attach 也是依賴 bpf() system call,背後是把 FD (file descriptor) 指向的程式跟一個 hook point 綁定
所以你想像一下,現在有一個封包進來你的機器,會碰到實體網卡 → Kernel → 經過 hook point 就會執行綁定的 BPF Program。
現在我們把上面的知識用一張圖來表示,就是下面這張圖!下面的例子是把 eBPF Program attach 到 TC ingress / egress 的 hook point
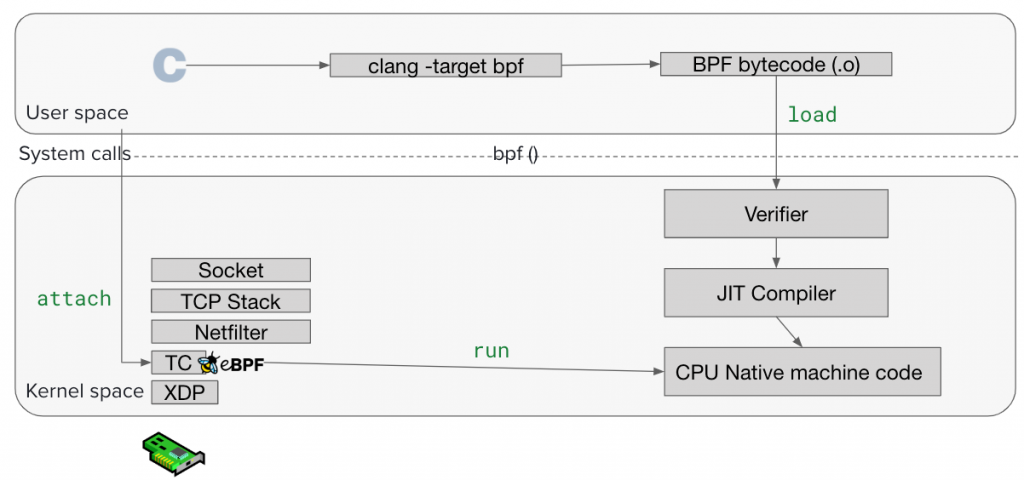
從 cBPF 到 eBPF 的演進,可以看到 BPF 最初是為了解決 tcpdump 效能問題而生,但隨著 Linux 社群的推動,eBPF 已經演變成一個通用的 Kernel Extensibility Framework。它透過 Verifier 確保安全、JIT Compiler 提升效能、以及 hook point 機制 讓我們能在 Kernel 的各種事件上動態插入程式碼。
掌握了「編譯成 Bytecode → Load 到 Kernel → 通過 Verifier → JIT → attach 到 hook point」這條流程,就能對 eBPF 的運作有清楚的全貌,也為後續理解 Cilium 打下基礎。

